文章摘要
【关 键 词】 大模型、自动化、代码能力、安全机制、性能跃升
Anthropic 正式发布了 Claude Opus 4.7 版本,标志着大模型在自动化工作流领域取得显著进展。新版模型具备独自执行更长、更复杂任务的能力,人类用户仅需在最终阶段验收成果。配合最新推出的 Routines 自动化工作流功能,大模型在自动化流程中实现了彻底松绑,简单设置后,用户无需持续干预即可完成工作。该功能支持灵活触发机制,包括定时运行、API 触发以及 GitHub 事件触发。即使在没有人工值守的情况下,系统也能自动唤醒处理代码审查请求、测试漏洞并生成报告。
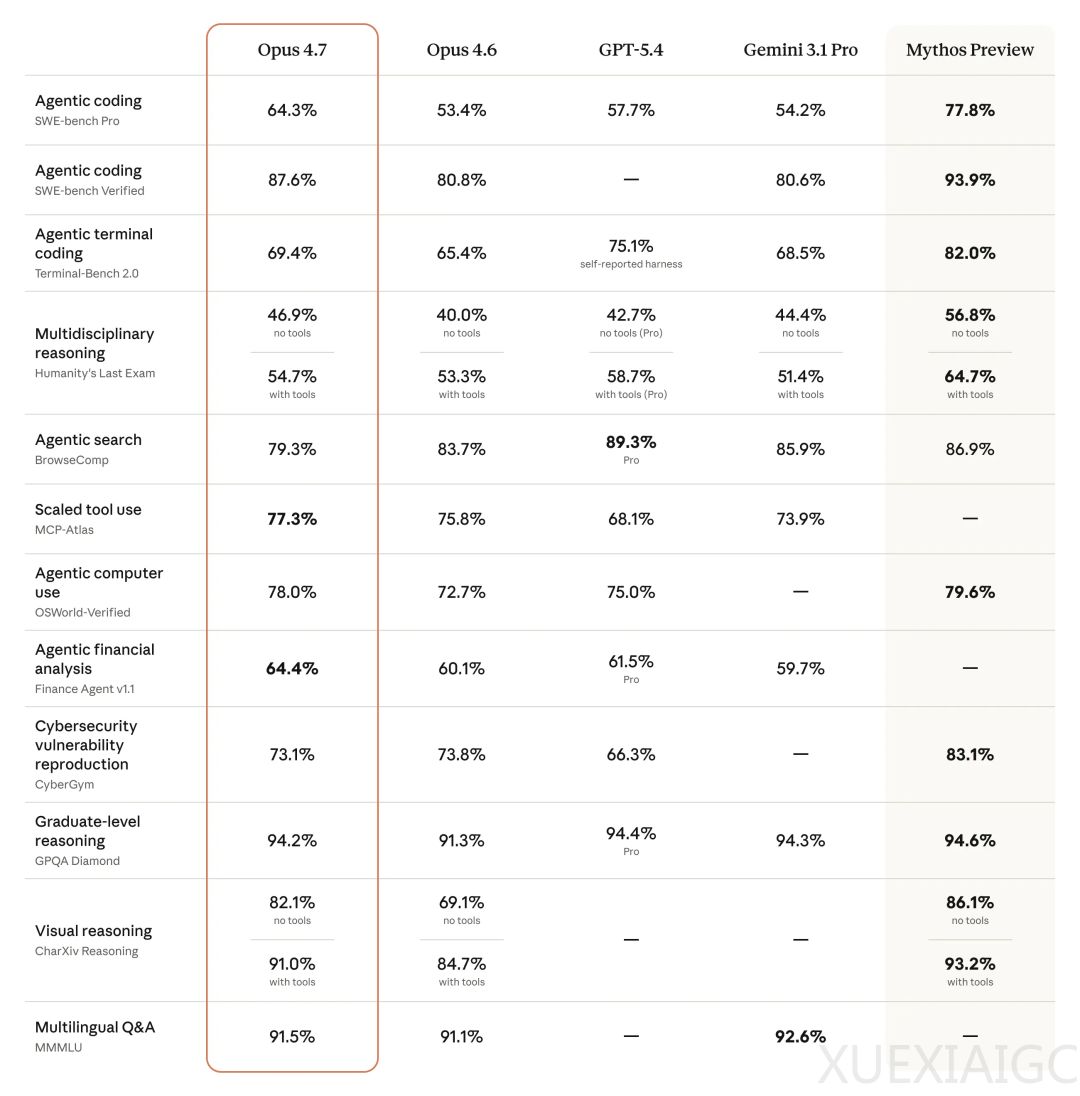
在性能方面,知识工作与办公能力得到明显增强。视觉能力支持最高 375 万像素图片输入,分辨率提升至以前的 3 倍以上。文档推理能力提升 23.5%,生物推理能力更是提升了 43.1%,长上下文推理也有所加强。代码能力进一步提升,在 Cursor 自家的 CursorBench 测试中,得分从 58% 直接冲到了 70%。Notion 团队测试反馈显示模型整体性能提升 14%,且首次通过了隐性需求测试,表明大模型懂得了工作默契,摆脱了只能听死命令的机械感。此外,配合自我纠错能力,Claude Code 新增了深度代码审查命令,一条命令即可跑轮深度审查。
安全机制与成本管控方面,官方引入了全新的护栏机制,结合网络安全项目部署了自动检测并拦截高风险用途的防护网。整体的安全基线保持稳定,欺骗,谄媚或协助滥用的发生率极低。定价方案保持原样,每百万 Token 输入 5 美元,输出 25 美元。为了提供细腻的控制粒度,系统推出了名为 xhigh 的全新运算级别,工程师可在推理深度和延迟之间找到最佳平衡点。高级用户获得了全新的自动模式权限,系统可代表人类做出决策以极少的打断次数跑完长周期任务。底层的分词器进行了升级,文本处理效率大幅提升,输入内容对应 1 倍到 1.35 倍的 Token 消耗,系统处理复杂问题时思考得更深入。
原文和模型
【原文链接】 阅读原文 [ 915字 | 4分钟 ]
【原文作者】 AIGC开放社区
【摘要模型】 qwen3.5-397b-a17b
【摘要评分】 ★☆☆☆☆


相关文章


