文章摘要
【关 键 词】 大模型、编程基准、程序重建、推理模式、性能突破
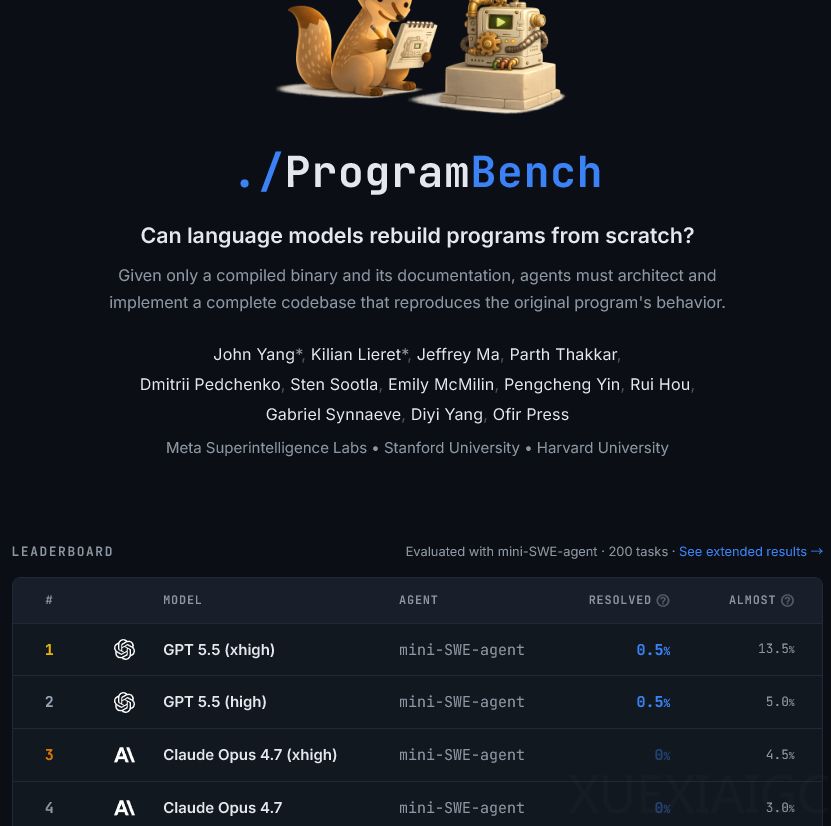
在编程能力评估领域,大模型技术近日取得显著进展。程序重建基准测试长期被视为极高难度的技术考验,要求智能体在仅获取编译文件与说明文档、严禁反编译且完全断网的严苛条件下,自主探测程序行为规律并完整重构源代码。该基准涵盖两百个复杂度各异的真实任务,验收环节依托模糊测试技术生成超过二十四万个针对性用例,任何细微偏差均直接判定失败,导致过往各类顶级模型的解决率始终停滞在零。
最新推出的GPT 5.5凭借高推理与超高推理模式,成功打破了该项基准长期零通过率的纪录。在默认中等推理配置下,模型表现相对平稳,但在获得更充裕的思考空间后,不仅斩获榜单设立以来的首个实例满分,更将单元测试通过率超过百分之九十五的任务数量大幅提升至二十六个。多维度数据对比表明,无论设定何种评估阈值,该模型在平均分、中位数及高通过率区间均占据领先地位,展现出对同类竞品的综合优势。
具体任务的重构过程揭示了不同模型的技术路径差异。各智能体在宏观策略上高度一致,均通过文档研读、命令行探针测试以及环境适配来制定单文件提交方案。GPT 5.5高推理模式在前期探测与后期编码之间实现了高效平衡,以极低的资源消耗完成了复杂逻辑的精准重建。模型经过多轮标志位组合测试彻底掌握程序特性后,直接输出完整的底层语言代码,并仅依赖少量补丁完成最终修复。这一结果验证了高层级推理机制在复杂软件工程决策中的实际效能,明确了大模型在极端受限环境下具备独立解决高难度编程任务的技术潜力。
原文和模型
【原文链接】 阅读原文 [ 1115字 | 5分钟 ]
【原文作者】 AIGC开放社区
【摘要模型】 qwen3.6-max-preview
【摘要评分】 ★☆☆☆☆

© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章

暂无评论...

