智子引擎发布多模态大模型 Awaker:MOE、自主更新、写真视频效果优于 Sora
文章摘要
【关 键 词】 多模态大模型、Awaker 1.0、自主更新、视频生成、VDT
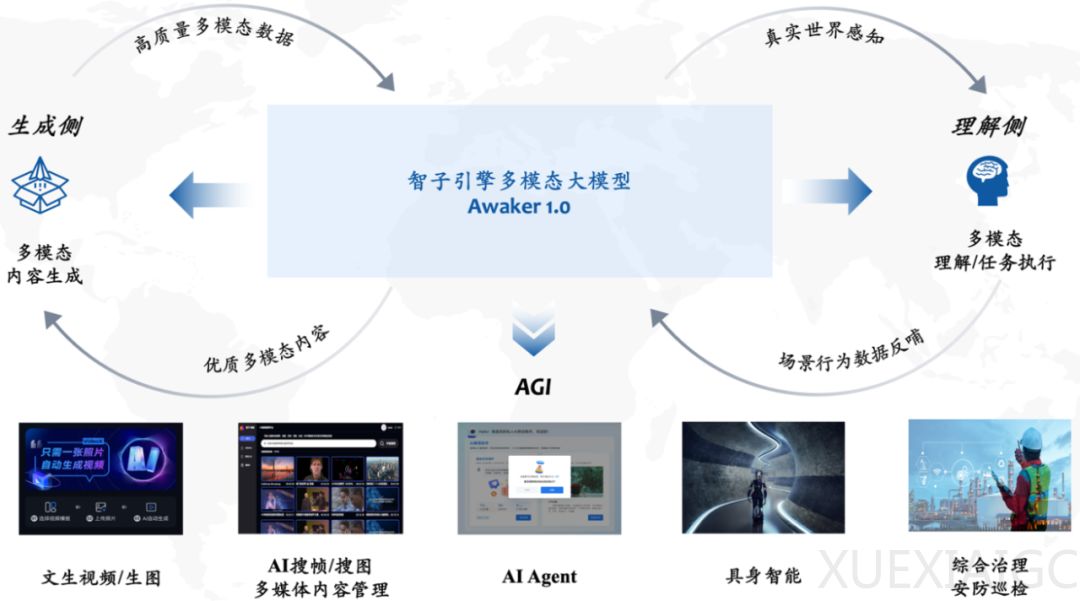
这个模型采用了MOE架构,并具备了业界首个「真正」自主更新的能力。
其性能在写真视频生成上超过了Sora模型,有望解决大模型在实际应用中的落地难题。
在理解方面,模型可以与数字世界和现实世界交互,通过场景行为数据的反馈实现持续更新和训练。
在生成方面,模型能够创造高质量的多模态内容,模拟现实世界,为理解侧提供更多训练数据。
Awaker 1.0的自主更新能力使其适用于更广泛的行业场景,如AI代理、具身智能、综合治理和安防巡检等。
它继承了前代模型ChatImg的基础能力,并学习了各个多模态任务所需的独特能力。
在多个任务上的性能都有显著提升,超过了国内外其他先进模型。
这使得Awaker 1.0成为一个「活」的模型,其参数可以实时持续更新。
模型能够与智能设备结合,通过设备观察世界,产生动作意图,并自动构建指令控制设备完成动作。
智能设备的反馈为模型提供了持续的训练数据,使其能够不断自我更新。
Awaker 1.0还能够不断学习互联网上的最新信息,并将新知识「记忆」在模型参数中。
VDT的研究成果已经被国际顶级会议ICLR 2024接收。
VDT的创新包括将Transformer技术应用于基于扩散的视频生成,提出统一的时空掩码建模机制,使其能够处理多种视频生成任务。
VDT在模拟简单物理规律方面表现出色,能够生成时间上连贯的视频帧。
其生成质量超过了Sora模型。
这些进展不仅提升了模型的适应性和创造性,还有望推动大模型在各行各业的实际应用。
未来,更通用的VDT将成为解决多模态大模型数据来源问题的有力工具,为Awaker的自主更新提供支持。
原文和模型
【原文链接】 阅读原文 [ 2875字 | 12分钟 ]
【原文作者】 Founder Park
【摘要模型】 gpt-4
【摘要评分】 ★☆☆☆☆


相关文章


