文章摘要
【关 键 词】 AI技术、图像生成、语义理解、视觉模型、创新方法
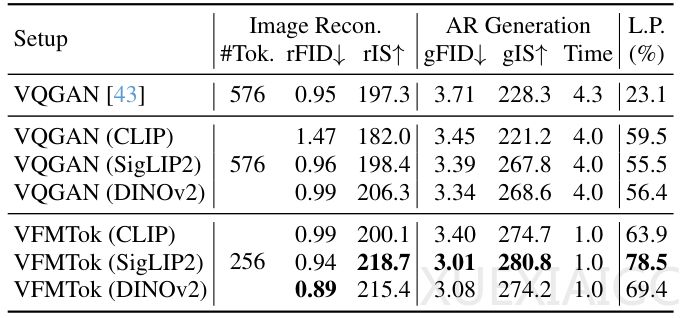
香港大学与阶跃星辰的研究团队开发了一种名为VFMTok的新方法,通过利用预训练的视觉基础模型(如DINOv2)作为高效的视觉分词器,显著提升了图像生成的速度和质量。该方法的核心在于将传统的像素级重建转变为对高级语义的理解,从而解决了自回归图像生成模型长期面临的瓶颈问题。传统的视觉分词器(如VQGAN)虽然能精确还原像素细节,但缺乏对图像内容的深层语义理解,导致生成过程冗长且依赖复杂的引导技术(如无分类器引导CFG)。VFMTok通过借用视觉基础模型的语义特征,实现了更高效的图像表示。
VFMTok的创新设计包括区域自适应采样和多级特征提取。该方法通过可学习的锚点查询和可变形交叉注意力机制,智能地识别图像中的语义一致区域,并将这些区域的特征聚合为紧凑的token。这种方式显著减少了空间冗余,仅需256个token即可实现高质量重建,而传统方法需要576个甚至更多。此外,VFMTok在训练中引入了特征重建目标,确保生成的token不仅保留低级细节,还与视觉基础模型的高级语义理解保持一致。实验表明,VFMTok在图像重建和生成任务中均达到最先进水平,其语义质量(L.P.得分)高达69.4,远超传统方法的23.1。
在ImageNet 256×256的类别条件生成任务中,VFMTok展现了卓越的性能。即使不依赖CFG技术,其1.4B参数的模型(VFMTok-XXL)仍能取得1.95的gFID分数,优于使用CFG的传统模型。这一结果表明,VFMTok的token本身具有极强的语义指向性,能够显著提升生成效率和质量。消融研究进一步验证了VFMTok各组件的重要性:冻结的视觉基础模型、区域自适应采样、多级特征融合以及特征重建目标,缺一不可。尤其是预训练的视觉基础模型,被证明是VFMTok成功的关键基石。
VFMTok的突破为自回归图像生成开辟了新路径。它不仅解决了传统方法的效率问题,还通过语义丰富的token实现了更自然的图像生成。这一技术的应用潜力广泛,未来可能在创意设计、虚拟现实等领域发挥重要作用。研究团队强调,VFMTok的成功得益于视觉基础模型的强大语义能力,这为后续研究提供了重要启示:结合预训练模型的优势,可能是突破生成模型瓶颈的有效策略。
原文和模型
【原文链接】 阅读原文 [ 3821字 | 16分钟 ]
【原文作者】 AIGC开放社区
【摘要模型】 deepseek/deepseek-v3-0324
【摘要评分】 ★★★★☆


相关文章


