CVPR 2026 | GaussianDWM:用3D高斯表示统一自动驾驶场景理解与多模态生成
文章摘要
【关 键 词】 自动驾驶、世界模型、三维高斯、场景理解、场景生成
自动驾驶世界模型的研究目标已从单纯预测未来视觉帧,扩展到构建可用于场景理解、空间定位和后续决策的统一世界表示。GaussianDWM框架致力于在统一的三维场景表示中同时支持驾驶场景理解与多模态生成任务。现有方法多依赖中间特征层对齐,缺乏真正的统一三维场景表征,而该研究选择以三维高斯作为场景底座,使同一组表示既能输入大语言模型进行理解,也能作为条件指导生成模块。
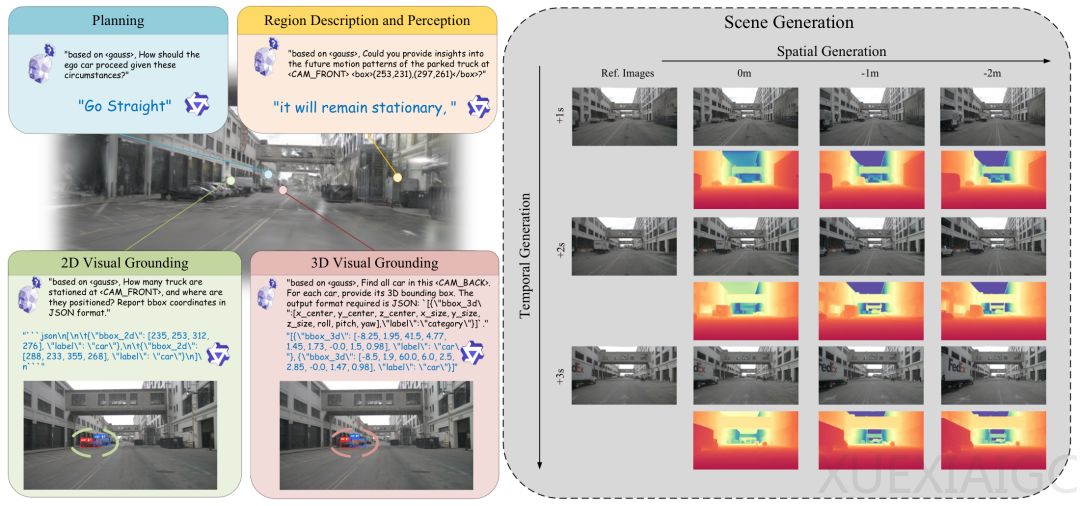
在场景理解方面,模型引入了语言增强的三维高斯分词器,将预训练模型的语言特征融入高斯原语,使每个空间单元携带语义信息。通过高斯投影器和任务感知采样机制,密集的三维高斯场被压缩并映射到大语言模型的嵌入空间,从而实现结构化的场景理解与视觉定位。在生成方面,模型采用双重条件生成设计,同时接收负责约束局部纹理和几何的低层视觉条件,以及由大语言模型提取的高层世界知识,以此强化生成过程中的场景关系与语义一致性。
实验结果表明,三维高斯表示为模型提供了明确的空间结构。在NuInteract数据集的评估中,该框架在二维和三维视觉定位任务上的平均指标显著优于现有基线方法,证明三维高斯能有效提升大语言模型对复杂驾驶环境的理解能力。在nuScenes数据集的空间生成任务中,模型在不同视角位移下均取得了更低的误差指标,在维持场景三维关系的前提下完成了高质量的视角变化。消融实验进一步证实,三维高斯表示、任务感知采样以及高层世界知识是支撑模型理解与生成能力的关键组件。自动驾驶世界模型不仅需要生成未来画面,更需形成可被理解、查询和用于规划的三维世界表示,以服务于复杂的动态交互与决策系统。
原文和模型
【原文链接】 阅读原文 [ 2230字 | 9分钟 ]
【原文作者】 机器之心
【摘要模型】 qwen3.7-max
【摘要评分】 ★★★★☆


相关文章


